在訓練的時候,經常會出現Overfitting的情況,也是就過度學習的情況,我一開始在實作的時候也遇過很多次,因此就去研究了一下,Overfitting是什麼,然後有那些常見的解決方法。什麼是Overfitting(過度學習)
Overfitting顧名思義就是過度學習訓練資料,變得無法順利去預測或分辨不是在訓練資料內的其他資料,我用個自己認知的簡單例子來表達 假設現在我要訓練一個模型可以辨識是不是貴賓狗,因此這個模型學習到貴賓的特徵:耳朵長而寬,頭較窄且長,尾巴與身體成一斜角,身體背部短之類的特徵,但因為訓練資料都給黑色的貴賓狗,所以模型過度依賴訓練資料而把黑色的特徵也學習起來了,因此在預估的時候遇到不同顏色的貴賓便會有準確度的問題,這就是過度學習。
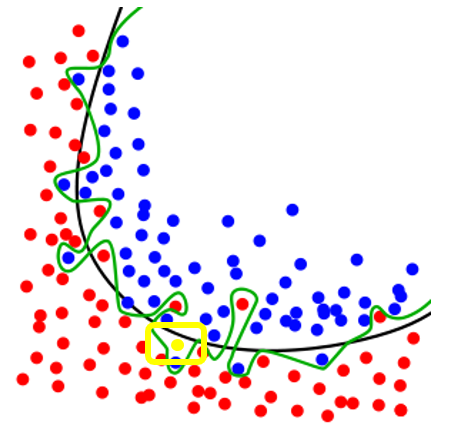
來自wiki,藍色跟紅色為當時訓練分類器的資料,黃色為新加入要分類的資料以上圖來看,綠線就是Overfitting的結果,黑線代表正常的分類模型,綠線雖然完全把訓練資料分類出來,但如果現在有一個新的資料進來(黃色點點),就會造成分類錯誤,因為綠色線的模型在訓練資料的準確率是非常高的,不過在新資料的分類下錯誤率變會提升,以下有個方法可以偵測是否有Overfitting的情況發生

將所有的Training data坼成二部分,一個是Training Set跟Validate Set,Training Set就是真的把資料拿去訓練的,而Validate Set就是去驗證此Model在訓練資料外的資料是否可行。(原來每個實作這樣做的原因是要去偵測Overfitting啊!!恍然大悟)機器學習的目標就是要訓練機器擁有人類的思考,並且擁有解決一般問題的能力,即使看到沒有包含在訓練資料的資料,也是要可以正確辨識的。而且現在訓練資料越來越龐大,訓練時間越來越久的時況下,避免跟解決Overfitting是機器學習上重要一個課題。 這裡有個連結,是用scikit-learn (python的一個學習套件,之後有時間會做介紹跟實作),來implement Underfitting 跟Overfitting在Linear Regression上的情況 http://scikit-learn.org/stable/auto_examples/model_selection/plot_underfitting_overfitting.html造成Overfitting的原因與解決方式
這個方法就是收集更多的資料,或是自行生成更多的有效資料(如果你生成一些跟模型無關的資料去訓練只會越來越糟 ,所以必需確正自行生成的資料對訓練模型是有幫助) - 減少參數或特徵或者是減少神經層數
- 在相同參數跟相同資料量的情況下,可以使用Regularization(正規化)
- 在相同參數跟相同資料量的情況下,可以使用Dropout
第一種方法其實就是在降低模型的大小,複雜的模型容易造成過度學習 第二種跟第三種下面會逐一介紹,此二種方法都是現在機器學習中常見用來防止Overfitting的方法。 Regularization (正規化)
Weight decay的意思就是對擁有較大權重的參數,課以罰金,藉此控制Overfitting的情況,因為Overfitting就是Weight 太大的時候可能會發生的問題。 Weight decay的方式就是在loss function (損失函數)加入參數權重的L2 norm,就可以抑制權重變大,我這邊就先不複習L2 norm是什麼,這個應該在線性代數裡面都有教過(但我其實也很久沒看線代有些忘了),我直接用以下公式來介紹 —
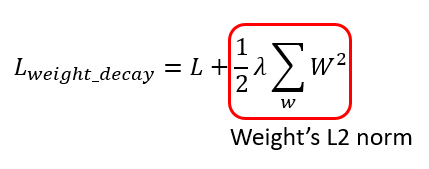
L2 norm就是把全部weight的平方和除2
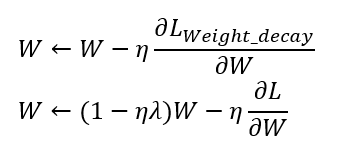
加入weight decay後的gradient decent 更新變更以上是使用Weight decay後的Gradient decent的參數更新推導, L是loss function,也就是損失函數,做Weight decay就是在loss function上加上Weight的L2 norm,進而推導出weight 更新就是上面的那個公式,可以看出跟原本的gradient decent更新比較,在一開始原本的weight乘上了(1- ηλ),因為 η,λ都為正,因此可以減少原本的weight的影響,越大的weight就變越小,越小的weight改變就不大,這就是Weight decay的由來。 另外補充一下,除了L2 norm以外,L1 norm跟L ∞ norm 都可以做為regular的方法。我們直接上一張圖來解釋Dropout的情況 —
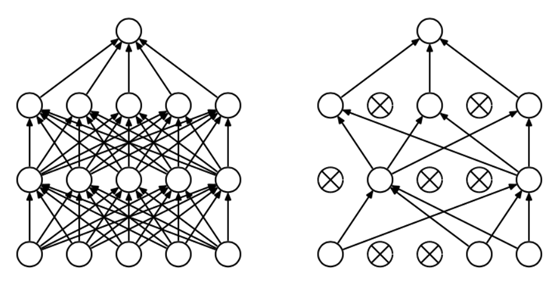
Dropout的情形,左邊為一般的深層網路,右邊為dropout過後的深層網路從上圖來看,經過dropout的網路,每一層都有神經元被打X,在消除上並沒有看見什麼規律性,因此我們可以看出Dropout的方法就是一邊"隨機”消除神經元,一邊訓練的方法。 我就直接拿Keras(python的一個Machine learning套件,之後有時間會做介紹跟實作)內建的dropout source code來做一個介紹,Keras的dropout code比較直觀,tensorflow內建的dropout必需使用tensor去完成,相對於Keras內建的code會比較難懂一些(我看了很久…),但觀念都是一樣的,有興趣的可以自行至以下網址研究https://github.com/tensorflow/tensorflow/blob/r1.10/tensorflow/python/ops/nn_ops.py - def dropout(x, level, noise_shape=None, seed=None):
-
- """
- #以下是參數介紹
- x:輸入
- level:0~1 的浮點數,需要被消除的神經元比例
- noise_shape : 整數張量,為將要應用在輸入上的二值Dropout mask的shape,例如你的輸入為(batch_size, timesteps, features),並且你希望在各個時間步上的Dropout mask都相同,則可傳入noise_shape=(batch_size, 1, features)
- seed : 隨機數種子
- """
-
- if level < 0. or level >= 1:
- raise ValueError('Dropout level must be in interval [0, 1[.')
- if seed is None:
- seed = np.random.randint(1, 10e6)
- if isinstance(noise_shape, list):
- noise_shape = tuple(noise_shape)
- #以上為參數check
-
- rng = RandomStreams(seed=seed)
-
- retain_prob = 1. - level
- #神經元能被保留的機率
-
- if noise_shape is None:
- random_tensor = rng.binomial(x.shape, p=retain_prob, dtype=x.dtype)
- #建立一個跟x一樣大小的白努利隨機函數 (0,1的隨機數列),p為是1的機率,也就是被保留的機率"
- else:
- random_tensor = rng.binomial(noise_shape, p=retain_prob, dtype=x.dtype)
- random_tensor = T.patternbroadcast(random_tensor,
- [dim == 1 for dim in noise_shape])
- x *= random_tensor
- #將輸入的input與0,1相乘,乘0的神經元就會被屏蔽,1的就會留下,這便是dropout隨機消除神經元的方法
- x /= retain_prob
- #將output做rescale,也就是所謂的inverted dropout,下面會介紹
-
- return x
從上面的code來看,其實就是這一層的神經元乘以一個白努利隨機數列(0,1的數列),乘以0的就是會被消除的神經元
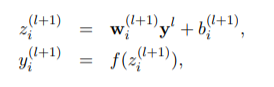
原本一般的神經網路公式(來自dropout論文)
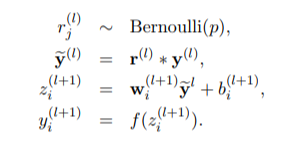
加入dropout的神經網路公式,乘上了白努利函數(來自dropout 論文)而在code最後有做了一個rescale,這是所謂的inverted dropout,因為使用dropout的時候,訓練只有 1-level比例的神經元會參與訓練,在預測的時候所有神經元都要參與,這樣的話結果相比於訓練時平均要大1/(1-level),所以在正常預測的時候要乘以1-level,然後在這裡做的就是inverted dropout,直接在訓練的時候做rescale,這樣在預測的時候就不會有這個問題了。
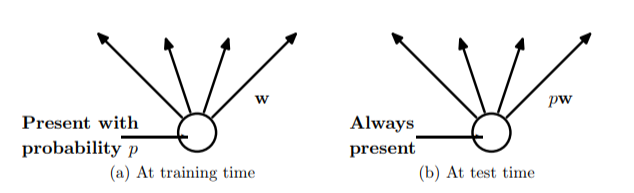
來自dropout 論文,以下有連結總結
Overfitting 對機器學習來說是常遇到的一個問題,不論是Regularization或是Dropout的技術都是很重要的一環,深入了解才會更加知道何時用Droput,何時用Reularization,這對之後遇到Overfitting有很大的幫助,解決了過度學習才有辦法訓練出一個完善的Neural Network 的Model。 參考資料
EliteDataScience 理解dropout Overfitting wiki Deep Learning 書籍
文章出處 | 


 IP卡
IP卡 發表於 2021-2-5 16:20:03
發表於 2021-2-5 16:20:03








 提升卡
提升卡 置頂卡(一天)
置頂卡(一天) 沉默卡
沉默卡 喧囂卡
喧囂卡 變色卡
變色卡 顯身卡
顯身卡